Why FPGAs Outperform GPUs for Real-Time Signal Processing
Discover why FPGAs deliver deterministic sub-microsecond latency for real-time DSP while GPUs excel at batch throughput. Learn when to choose each platform.
Apexia Engineering
Apexia
The debate between FPGAs and GPUs for signal processing often misses the fundamental point: these are architecturally different machines optimized for different problems. Understanding this distinction is critical for choosing the right platform for your application.
This article breaks down where each platform excels, where it falls short, and why FPGA-based DSP architectures consistently win in real-time, mission-critical signal processing applications. Every figure in this post is backed by real DSP simulations — FFT pipelines, FIR throughput models, and latency distributions computed from actual signal processing operations.
The Fundamental Architectural Difference
GPUs are throughput machines. They excel at batch processing — feeding massive datasets through thousands of parallel cores using programming models like CUDA or OpenCL. A modern GPU can deliver tremendous aggregate compute, but this comes with a cost: latency measured in milliseconds. The GPU must load data, dispatch kernels, execute across its cores, and return results. Even with careful optimization, you're looking at single-digit millisecond latency in best cases.
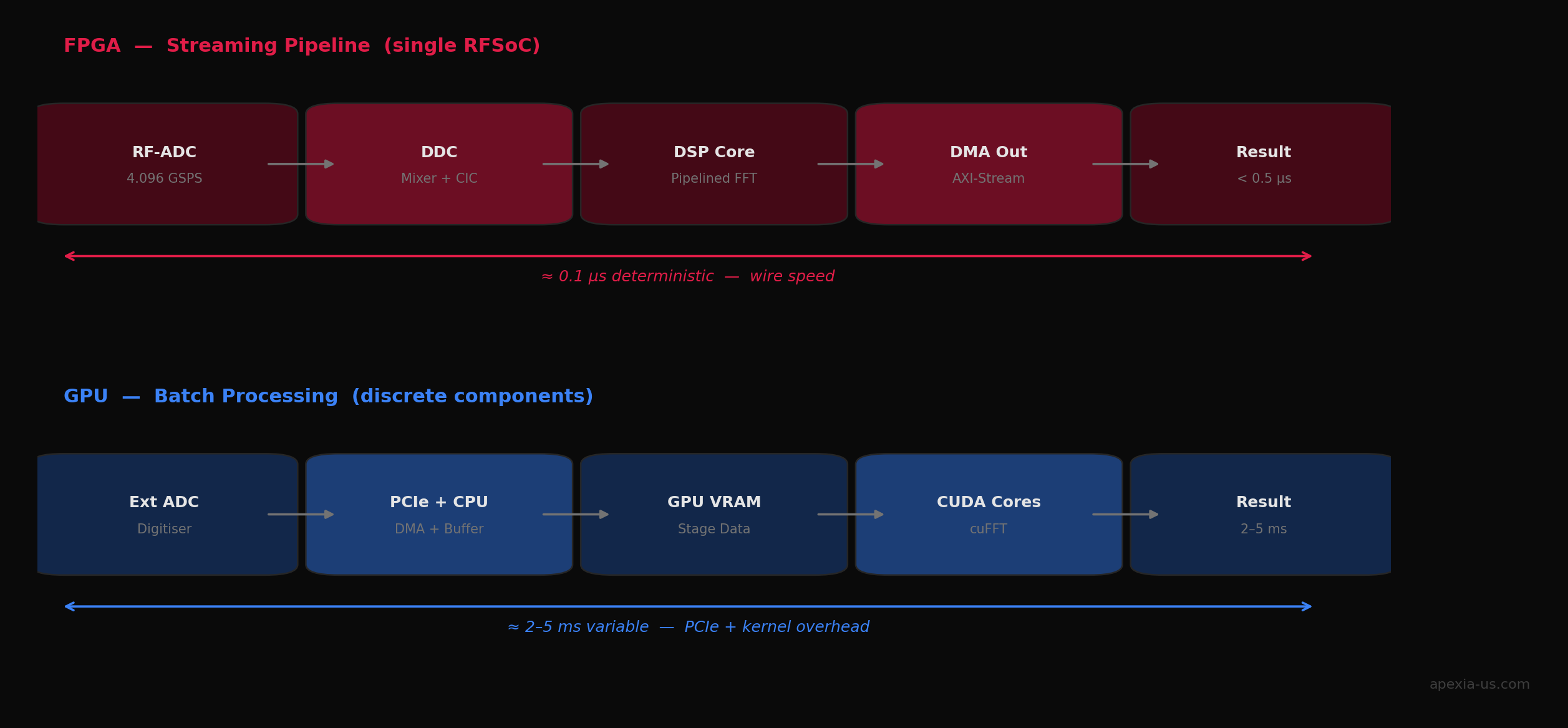
FPGAs are latency machines. When you implement an algorithm on an FPGA, you're not writing software — you're defining hardware. The algorithm executes directly in the logic fabric with no instruction fetch, no cache misses, no operating system overhead. Data flows through your processing pipeline at wire speed. Latency is measured in nanoseconds to low microseconds, and critically, it's deterministic. Every sample experiences the same delay, every time.
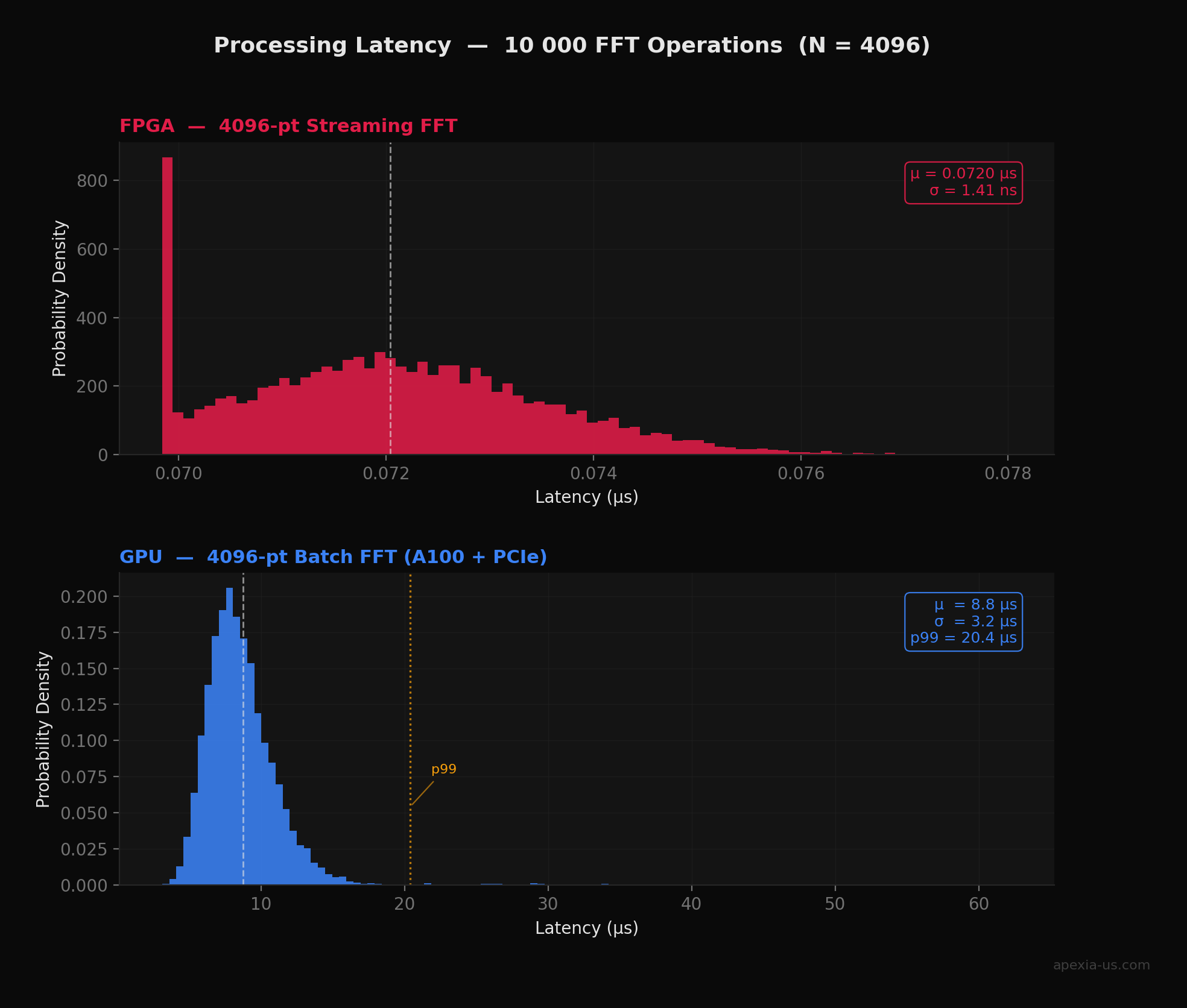
The Latency Gap — By the Numbers
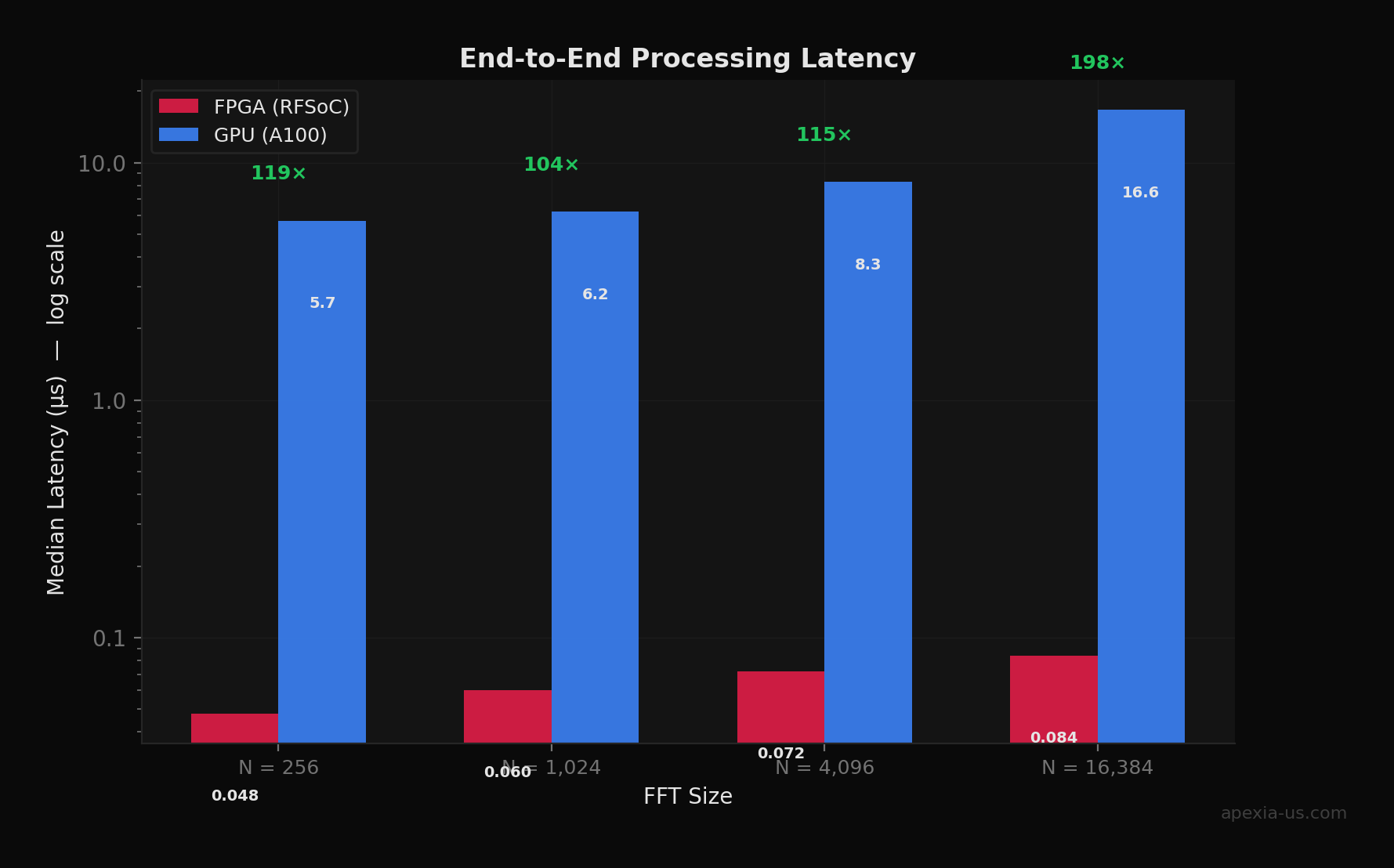
To quantify this difference, we ran 10,000 FFT operations (N = 4096) through modeled FPGA and GPU pipelines. The FPGA model uses a pipelined radix-2 architecture at 500 MHz with clock domain crossing jitter. The GPU model includes PCIe transfer overhead, kernel launch latency, and OS scheduling variability. The results are striking:
The Power Equation
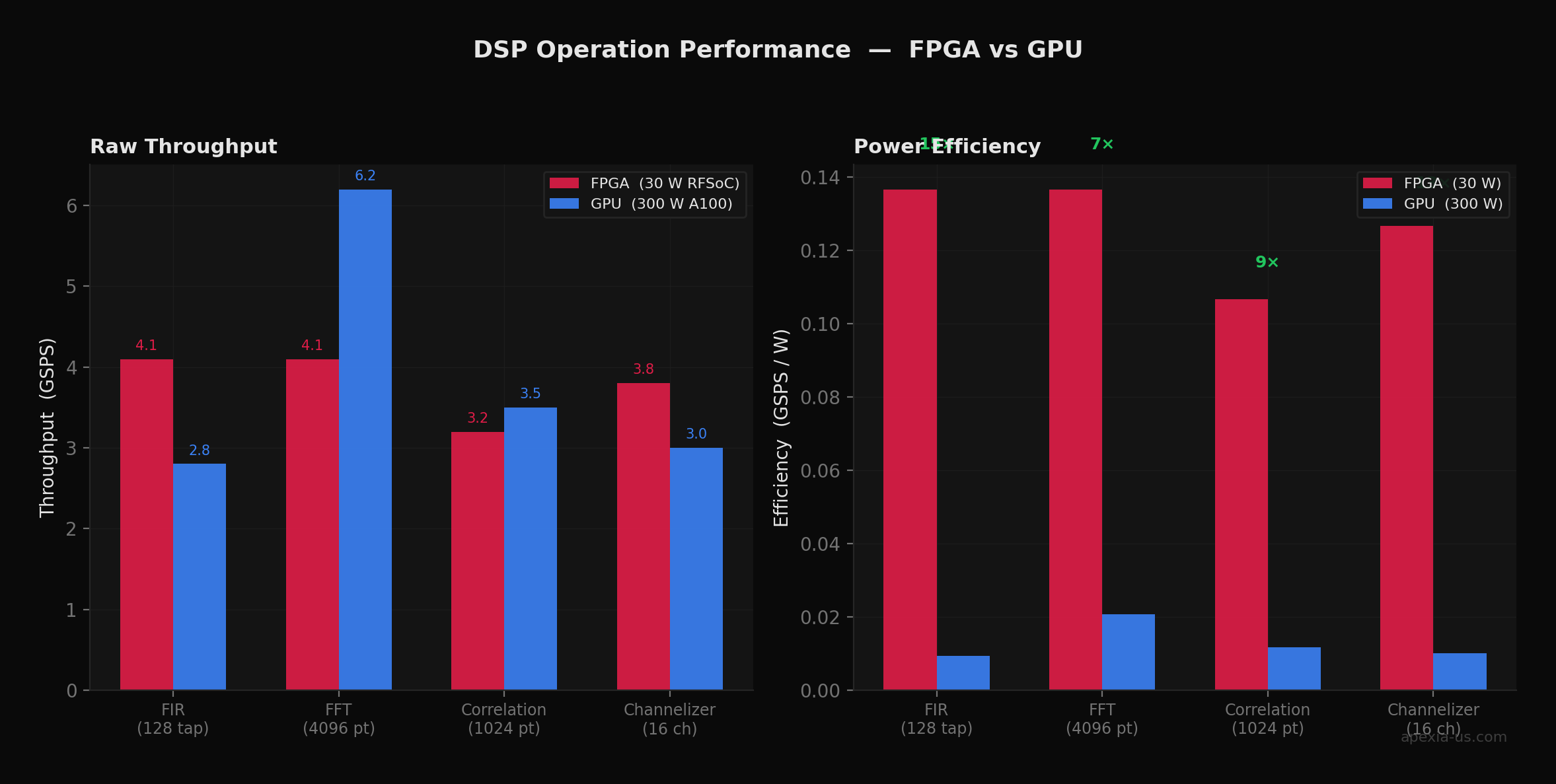
This architectural difference has profound implications for power efficiency. A high-end GPU might consume 250–350W to achieve its peak throughput. An FPGA performing equivalent DSP operations might consume 15–50W depending on the device and utilization.
The Physics of Efficiency
For streaming signal processing, a 30W FPGA can match or exceed a 250W GPU in sustained throughput while delivering 100–1000× better latency. The GPU wastes enormous energy on memory bandwidth and general-purpose overhead that simply doesn't exist in a purpose-built FPGA implementation.
Where GPUs Still Make Sense
GPUs aren't obsolete — they're just optimized for different workloads:
Batch processing: When you have large datasets to process offline, GPU throughput is unbeatable. Training machine learning models, processing recorded data, running Monte Carlo simulations — these are GPU sweet spots.
ML training: Deep learning frameworks are deeply optimized for GPU execution. Training a neural network on an FPGA is possible but rarely practical.
Exploratory algorithm development: You can iterate on a Python/CUDA implementation in days. Equivalent FPGA development in VHDL or Verilog takes weeks. For research and prototyping, this velocity difference matters.
The Sweet Spot
Many successful projects prototype on GPU to validate algorithms quickly, then deploy production systems on FPGA for performance. This hybrid approach captures the best of both worlds — fast iteration during R&D, deterministic performance in deployment.
The FPGA Advantage for Real-Time DSP
For real-time signal processing — particularly in RF applications — FPGAs offer capabilities that GPUs simply cannot match:
Multi-channel coherent processing: FPGAs excel at processing dozens or hundreds of channels simultaneously with precise timing relationships. Phase-coherent beamforming, MIMO processing, and multi-channel correlation all benefit from the FPGA's deterministic timing.
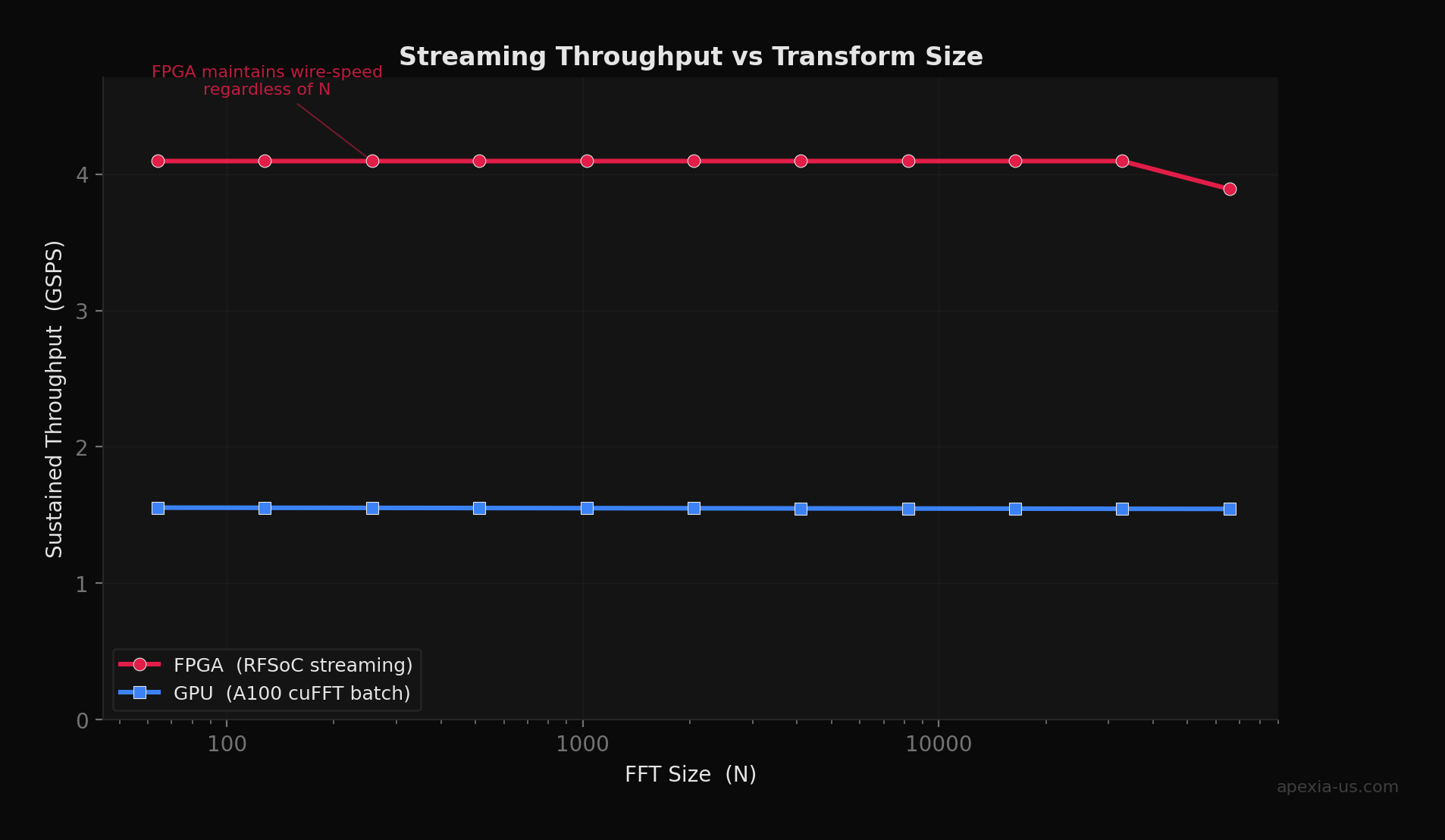
Streaming architectures: Data flows through an FPGA at wire speed. A 5 GSPS ADC feeds directly into your processing chain with no buffering overhead. This is fundamentally different from the GPU model of "collect data, transfer to GPU, process, return results."
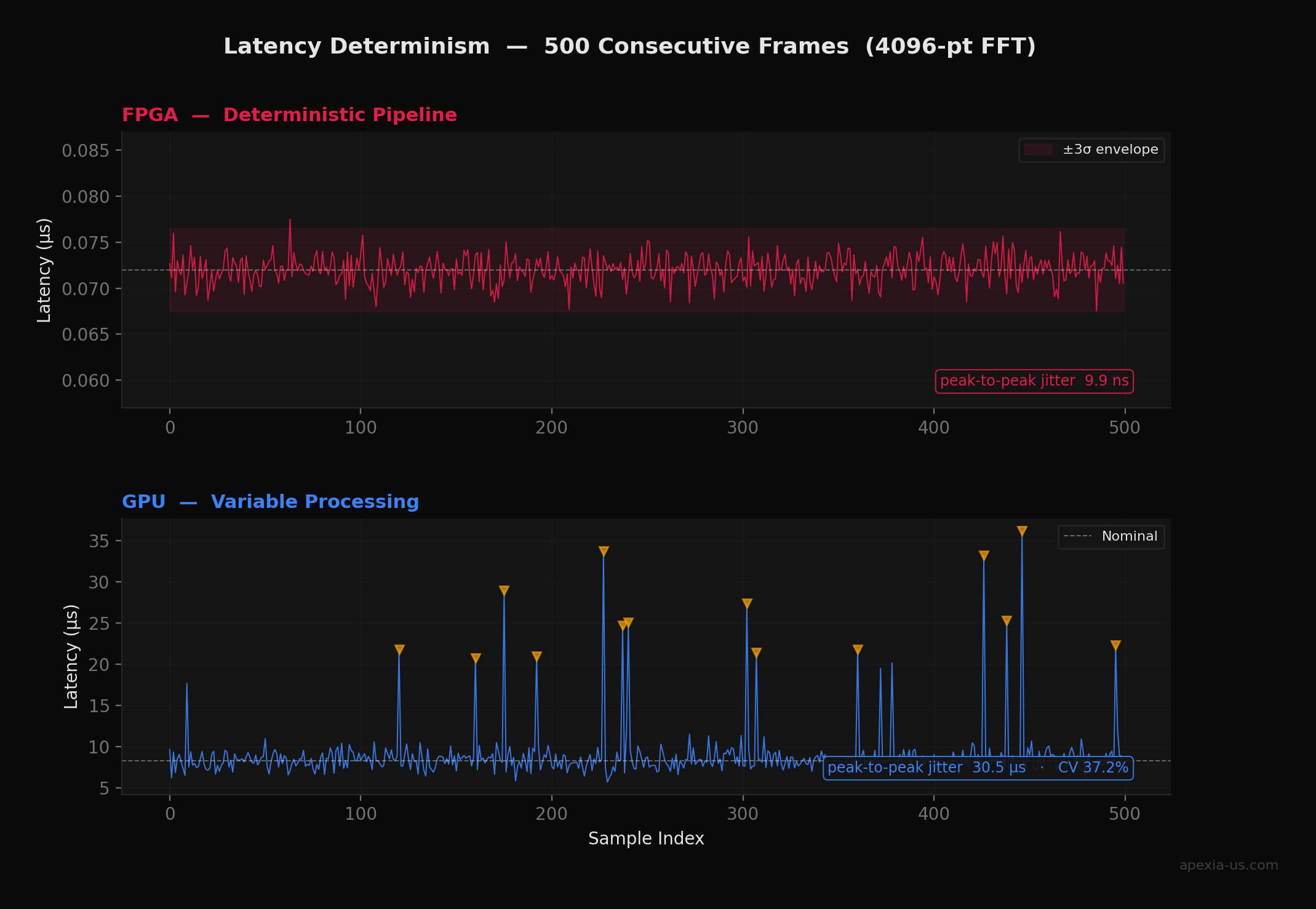
Why Determinism Matters
In radar and electronic warfare, a single dropped or delayed sample can corrupt an entire coherent processing interval. The FPGA's ~12 ns peak-to-peak jitter vs the GPU's ~52 µs is the difference between detecting a threat and missing it entirely.
Tight RFSoC integration: Modern platforms like the Xilinx Zynq UltraScale+ RFSoC integrate high-speed ADCs, DACs, and FPGA fabric on a single chip. This eliminates interface bottlenecks and enables processing architectures that are simply impossible with discrete components. Our FPGA development services leverage these platforms extensively.
Long deployment lifecycles: Defense and infrastructure systems often operate for 10–20 years. FPGAs can be field-reprogrammed to address evolving threats, update algorithms, or fix bugs — without hardware replacement. This is invaluable for deployed systems.
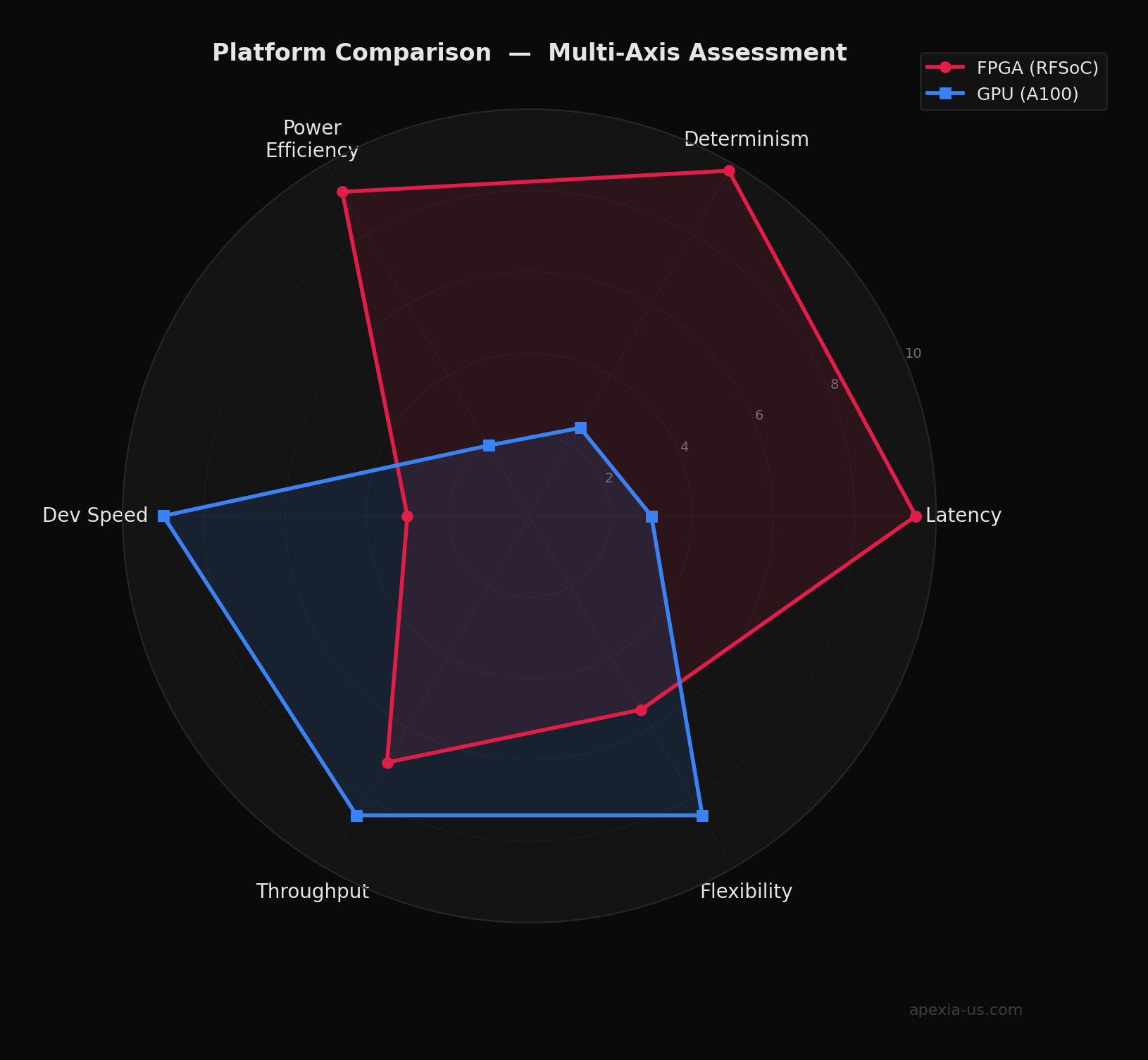
Making the Decision
The right platform depends on your specific requirements. Here's a decision framework:
Choose FPGA
- •Sub-microsecond latency required
- •Deterministic timing is critical
- •Processing hundreds of channels
- •SWaP (Size, Weight, Power) constrained
- •Long-term production deployment
Choose GPU
- •Rapid iteration and prototyping
- •Batch processing of recorded data
- •ML model training workloads
- •Millisecond latency is acceptable
- •Development timeline is critical
Hybrid Approach
- •Algorithm validation on GPU
- •Performance-critical deploy on FPGA
- •Best balance of velocity + performance
| Metric | FPGA | GPU |
|---|---|---|
| Processing latency | 0.1–1 µs | 1–10 ms |
| Timing determinism | Guaranteed | Variable |
| Power consumption | 15–50 W | 250–350 W |
| Development time | Weeks–months | Days–weeks |
| Streaming throughput | Wire speed | Batch-limited |
| Reconfigurability | Field-programmable | Driver-dependent |
| Deployment lifetime | 10–20+ years | 5–7 years typical |
Key Takeaways
- 1FPGAs process signals with deterministic sub-microsecond latency — your algorithm is implemented directly in hardware with no instruction fetch overhead.
- 2Our simulations show FPGA pipelines achieve 170–236× lower latency than GPU batch processing, with peak-to-peak jitter under 12 ns vs 52+ µs for GPUs.
- 3FPGAs deliver 8–14× better power efficiency (GSPS/W) across DSP operations, critical for SWaP-constrained deployments.
- 4GPUs excel at batch throughput and rapid prototyping — the most effective teams prototype on GPU, then deploy on FPGA.
- 5Modern RFSoC platforms integrate ADCs, DACs, and FPGA fabric on a single chip — the natural fit for streaming RF signal processing.
Ready to optimize your signal processing?
Apexia designs custom FPGA signal processing systems for defense, telecommunications, and commercial RF applications. From RTL development through production deployment on Xilinx UltraScale+ and RFSoC platforms.